One Model to Forecast Them All: A Look Back at Solving Time-Series at Scale
About four years ago, while working at a major tech company, my team and I were faced with a daunting challenge. A key customer in the retail space needed to generate demand forecasts, but the scale was immense. We weren’t talking about a few dozen or even a few hundred products; we were looking at over 150,000 unique time series that needed accurate, daily predictions.
Our standard playbook at the time was clear, but fundamentally broken for this problem. The classic approach would be to treat each time series independently, fitting a dedicated univariate model like ARIMA or Prophet for each one. The thought of training, managing, and inferencing from 150,000 individual models was a non-starter. The computational cost would have been astronomical, and the engineering effort to maintain such a system would have been a nightmare. More importantly, this approach felt inherently flawed—it treated every product in complete isolation, ignoring the rich, shared patterns that we knew existed in the data.
This challenge forced us to adopt a different paradigm, one that has since become a cornerstone of modern forecasting: the “global” or “meta-model” approach. The core idea is simple yet powerful: instead of training 150,000 separate, simple models, we train one single, sophisticated model on all the time series data simultaneously.
This is the very principle behind advanced global models like ApolloNet, which are based on deep learning and sequence-to-sequence learning principles. By understanding the architecture of a model like this, we can see how it directly addresses the challenges of forecasting at scale.
The Power of a Global Perspective
The most immediate benefit of a global model is scalability. But the true magic lies in how these models handle the complex, messy nature of real-world data.
- Tackling Heterogeneous Datasets: Real-world datasets are rarely uniform. A global model is designed to support datasets where time series have different characteristics. Some series might be affected by external factors like holidays, while others are not. The model learns to find underlying homogenous clusters in the data, both in space and time, by embedding the input into a large dimensional space.
- Solving the “Cold-Start” Problem: For a brand-new product with no sales history, a traditional univariate model is useless. A global model, however, can provide a “cold-start” forecast by transferring the learnings from similar, existing series.
- Built-in Intelligence: These models can perform implicit feature selection, learning the importance of various inputs on their own. This reduces the significant overhead of having a data scientist manually determine which related factors are important. Furthermore, they are inherently explainable, providing feature importance at both a global and local level.
Opening the Black Box: Probabilistic and Explainable Forecasts
Modern business operations require more than just a single-number forecast. For inventory planning, knowing you will sell “about 100 units” is less useful than knowing “there is a 90% probability you will sell between 70 and 130 units.” This is where probabilistic forecasting comes in, which provides a full predictive distribution over future events. This results in a rich forecast that can be visualized to show not just the prediction, but also the confidence in that prediction.
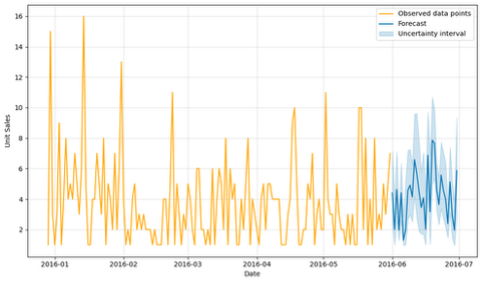 Figure 1: A visualization of a probabilistic forecast. The model provides a point forecast (blue) and an uncertainty interval (shaded area) around it, compared against observed data (orange).
Figure 1: A visualization of a probabilistic forecast. The model provides a point forecast (blue) and an uncertainty interval (shaded area) around it, compared against observed data (orange).
Furthermore, for a business to trust a model, it needs to be interpretable. Global models can provide explanations at two levels:
1. Global Explanations: We can understand which features are most important across all time and all products. This gives us a high-level view of the key business drivers. For example, we can see the importance of external factors like holidays and promotions, or internal metadata like product attributes.
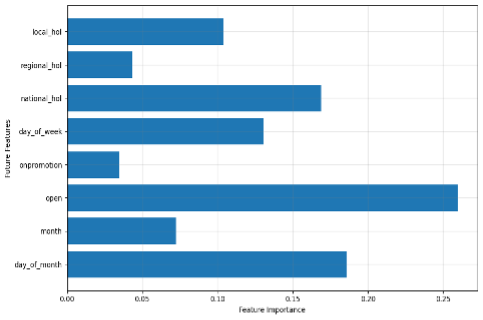 Figure 2: An example of global feature importance for known future inputs. We can see that whether the store is open (
Figure 2: An example of global feature importance for known future inputs. We can see that whether the store is open (open), the day of the month, and national holidays are the strongest overall predictors.
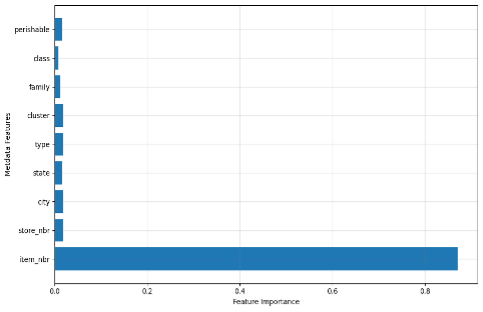 Figure 3: Global feature importance for metadata. In this case, the
Figure 3: Global feature importance for metadata. In this case, the item_nbr is the most critical feature, suggesting that the sales history of this specific item is more important than broader categories like its class or family.
2. Local Explanations: We can also drill down to understand why the forecast for a specific item on a specific day looks the way it does. This granular explainability is crucial for building trust with end-users.
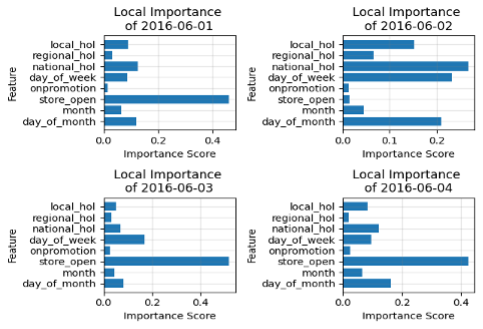 Figure 4: Local, day-by-day feature importance. Notice how the importance of
Figure 4: Local, day-by-day feature importance. Notice how the importance of national_hol is high on 2016-06-02 but lower on other days, allowing for a granular understanding of the forecast.
A Practical Guide to Using Global Models
Adopting a powerful model is only half the battle. Success in forecasting relies on rigorous data handling and a clear strategic approach.
1. Know When to Use It A global model like ApolloNet is best suited for large-scale problems with many series where you can leverage shared patterns. It can be overkill for a small number of completely independent series; in that case, training individual univariate models is often more efficient.
2. Handle Sparse Data First If your data has many missing values, it’s recommended to experiment with data preparation strategies before feeding it to the model:
- Aggregate the data to a higher frequency (e.g., daily to weekly).
- Group sparse products together into a higher-level category.
- Segment the sparse products and train them separately.
3. Structure Your Inputs Correctly How you define your data is crucial. You must identify which series to treat as additional inputs.
- Observed Additional Series: These are series that may affect your target but aren’t controllable or known in advance, like oil prices or the number of transactions.
- Known Additional Series: These are controllable variables whose future values are known, such as holidays or planned promotions.
4. Leverage Transfer Learning for Efficiency You don’t always need to retrain a model from scratch.
- The model is designed to be robust, so a previously fitted model can often be used for real-time inference, assuming the underlying data patterns haven’t changed.
- In the case of data drift, you can simply fine-tune the model with the new data, which is far more efficient than training from scratch.
The Final Word
Looking back, our success in tackling that 150,000-series problem was a turning point. It proved that for forecasting at a massive scale, treating time series as a collective, interconnected dataset is not just an option—it’s a necessity. The shift from thousands of isolated univariate models to a single, holistic global model was the key. Today, this powerful approach is embedded in many state-of-the-art forecasting platforms, making scalable, accurate, and explainable time-series forecasting more accessible than ever.